DreamZero: World Action Models are Zero-shot Policies
State-of-the-art Vision-Language-Action (VLA) models excel at semantic generalization but struggle to generalize to unseen physical motions in novel environments. We introduce DreamZero, a World Action Model (WAM) built upon a pretrained video diffusion backbone. Unlike VLAs, WAMs learn physical dynamics by jointly predicting future world states and actions, using video as a dense representation of how the world evolves. By jointly modeling video and action, DreamZero learns diverse skills effectively from heterogeneous robot data without relying on repetitive demonstrations. This results in over 2x improvement in generalization to new tasks and environments compared to state-of-the-art VLAs in real-robot experiments. Crucially, through model and system optimizations, we enable a 14B autoregressive video diffusion model to perform real-time closed-loop control at 7Hz. Finally, we demonstrate two forms of cross-embodiment transfer: video-only demonstrations from humans or other robots yield over 42% improvement on unseen tasks with just 10–20 minutes of data. More surprisingly, DreamZero adapts to an entirely new robot (YAM) with only 30 minutes of play data while retaining zero-shot generalization.
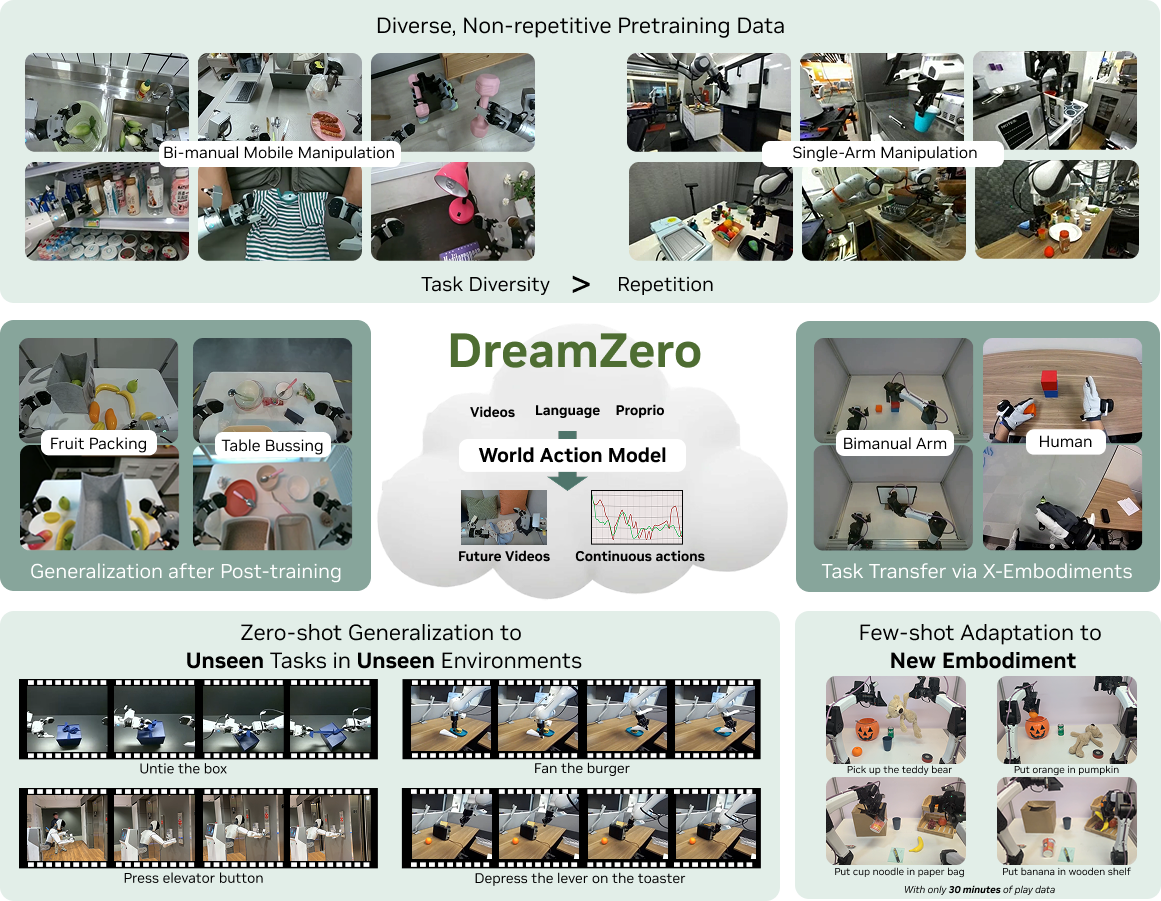
We show DreamZero's capability across six settings—five testing generalization, and one demonstrating real-time deployment:
1AgiBot Pretraining: Seen & Unseen Tasks
We evaluate pretrained models out-of-the-box on tasks from the pretraining distribution, but in zero-shot environments with unseen objects. DreamZero (also trained from scratch) achieves 62.2% average task progress—over 2× higher than the best pretrained VLA baseline (27.4%). VLAs trained from scratch achieve near-zero performance, while pretrained VLAs show modest progress. For tasks entirely absent from training—such as untying shoelaces and shaking hands—DreamZero reaches 39.5% task progress while VLAs again struggle. Notably, the limited task progress from pretrained VLAs on unseen tasks stems from defaulting to pick-and-place motions regardless of the instruction, suggesting they overfit to dominant training behaviors rather than understanding novel task semantics. We evaluate 80 rollouts per checkpoint across 4 robots, each in different environments with different objects.
Seen Tasks:
Unseen Tasks:
* Some videos were recorded before final inference optimization integration. See Section 3 for our smoothest real-time rollouts.
2DROID: Seen Tasks & Unseen Verbs
To validate on publicly available data, we train DreamZero on DROID—one of the most heterogeneous open-source robotic datasets. We evaluate on 20 seen tasks and 20 tasks with unseen verbs (actions absent from DROID). DreamZero outperforms pretrained baselines, achieving 49% task progress on unseen verbs compared to 25-32% for state-of-the-art VLAs.
3Post-Training: Out-of-Distribution Generalization
We investigate whether WAMs retain their generalization after being fine-tuning on task-specific data. We post-train on three downstream tasks : shirt folding, fruit packing, and table bussing. DreamZero enables stronger post-training results across three tasks, indicating that environment generalization is retained after post-training.
Table Bussing (5 trash & 5 dishware): 10 consecutive evaluations | Task Progress: 81%
* This is a uncut recording of a single evaluation session.
4New Embodiment Adaptation
With only 30 minutes of play data (55 trajectories), DreamZero adapts to the YAM robot and generalizes zero-shot to novel objects like pumpkins, teddy bears, and paper bags, exhibiting strong language following capabilities. The knowledge gained from AgiBot pretraining transfers directly—no massive retraining required. To our understanding, this is the most efficient embodiment transfer yet—what previously demanded hundreds of hours of demonstrations, we accomplish in 30 minutes (no other YAM data was used). See the full 30-minute play dataset here.
Put the cup noodle in the paper bag | ✅
5Interactive Prompting
The era of prompting robot foundation models has arrived. In this section, we show some rollouts of interactive prompting in action, where we take the robot around, and just ask people to prompt the robot to do new things. Here are some cool tasks that we found the robot is able to do.
Prompt | "Move forward and press the elevator button with right arm"
6Real-Time Inference & DreamZero-Flash
Through model, system, and implementation optimizations, DreamZero achieves real-time inference at 150ms per action chunk—enabling 7Hz closed-loop control. Combined with asynchronous inference and action chunk smoothing, this results in smooth, responsive execution. Below we compare rollouts using 16, 4, and 1 diffusion steps: fewer steps reduce latency while DreamZero-Flash maintains performance even at single-step inference. We additionally show the effect of action chunk smoothing and asynchronous inference on execution quality.
What's Next?
How far can zero-shot generalization go? We've been stress-testing DreamZero with tasks we never trained on, in environments we've never seen. From fanning burgers to pressing elevator buttons, playing xylophones to shaking tambourines, we keep discovering surprising new capabilities. DreamZero is just the beginning of the new wave of robot foundation models built on video world models!
Citation
If you find this work useful, please cite our paper:
@misc{ye2026worldactionmodelszeroshot,
title={World Action Models are Zero-shot Policies},
author={Seonghyeon Ye and Yunhao Ge and Kaiyuan Zheng and Shenyuan Gao and Sihyun Yu and George Kurian and Suneel Indupuru and You Liang Tan and Chuning Zhu and Jiannan Xiang and Ayaan Malik and Kyungmin Lee and William Liang and Nadun Ranawaka and Jiasheng Gu and Yinzhen Xu and Guanzhi Wang and Fengyuan Hu and Avnish Narayan and Johan Bjorck and Jing Wang and Gwanghyun Kim and Dantong Niu and Ruijie Zheng and Yuqi Xie and Jimmy Wu and Qi Wang and Ryan Julian and Danfei Xu and Yilun Du and Yevgen Chebotar and Scott Reed and Jan Kautz and Yuke Zhu and Linxi "Jim" Fan and Joel Jang},
year={2026},
eprint={2602.15922},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2602.15922},
}